Cursor, Claude Code, Copilot, and Codex and other AI coding assistant already have strong harnesses.
They can read files, edit code, search a repo, run commands, call MCP tools, and manage context better than most custom agents. For greenfield work, that base harness is often enough.
Brownfield enterprise work is different.
A real enterprise codebase is not one clean repo. It is usually ten repos, shared libraries, old deployment scripts, hidden contracts, brittle tests, tribal rules, and service boundaries nobody fully remembers.
That is where the next harness layer matters.
The winning pattern is not:
Build your own Cursor from scratch.
It is:
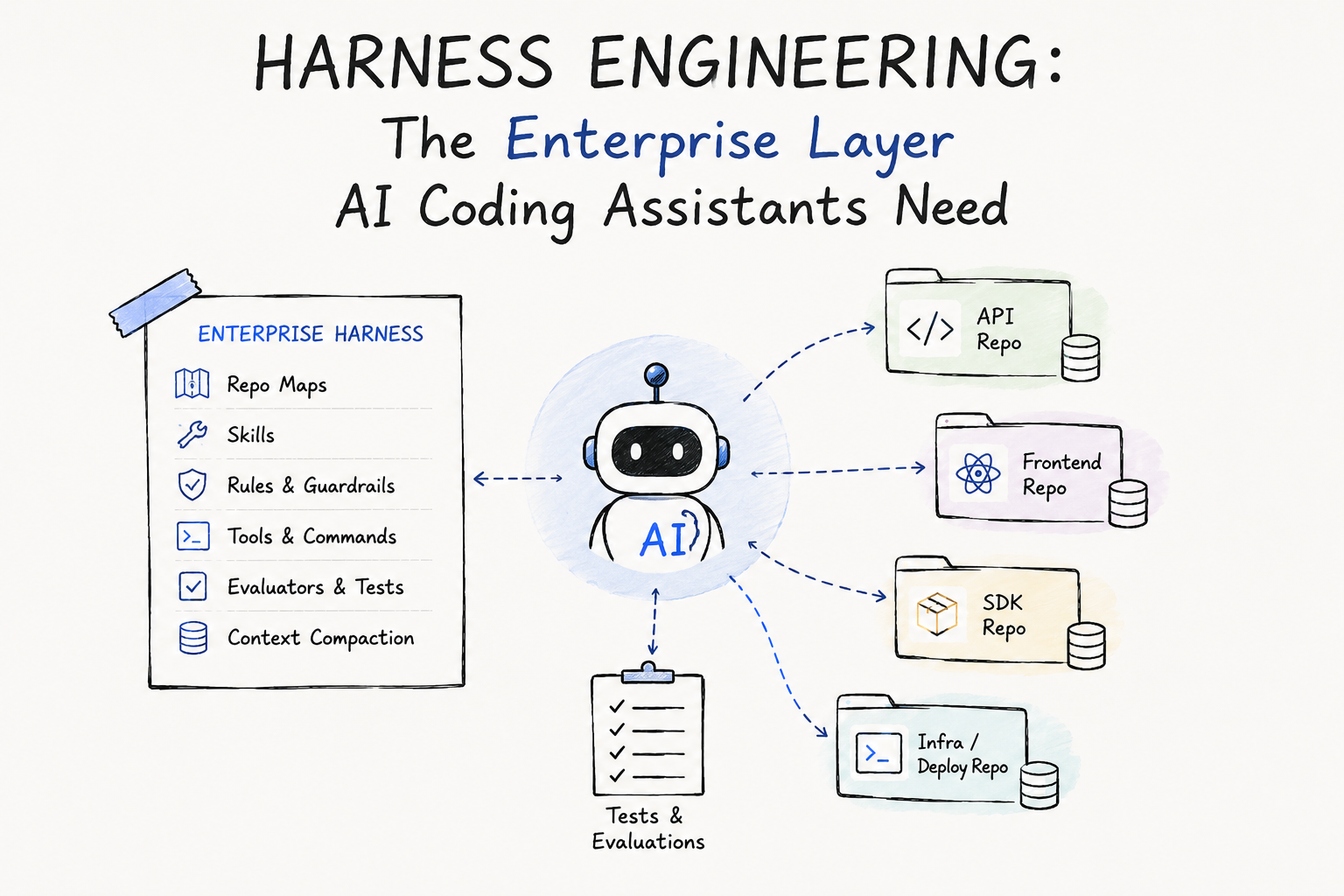
Put an enterprise, domain-aware harness around the coding assistant you already use.

Agent = Model + Harness
The simple equation is:
Agent = Model + Harness
For enterprise coding, I would extend it:
Useful enterprise agent = Base coding assistant + domain-aware harness
The base assistant gives you general coding capability. The enterprise harness gives you local correctness.
The model may know how to write a migration. It does not know that your payments repo requires a rollback note, your API repo requires OpenAPI updates, and your frontend repo consumes generated SDKs from a separate package.
That knowledge has to live somewhere.
It should live in the harness.
The Base Harness Is Already Good
I would not start by rebuilding what Cursor, Claude Code, Copilot, or Codex already provide.
They already handle file editing, terminal access, repo search, tool calls, MCP integration, and context management. That is hard infrastructure.
The gap is not “can the agent code?”
The gap is:
Does the agent understand how this company ships software?
In brownfield projects, the assistant needs to know which repo owns what, which commands are safe, which folders are dangerous, which contracts must be updated, and which tests actually prove the change works.
Without that layer, the assistant can produce code that looks right and still breaks the system.
Brownfield Repos Break Naive Agents
A common failure looks like this.
The agent changes an API response in orders-service. It updates the TypeScript type and the UI compiles. Then it says the task is done.
But it missed openapi.yaml.
Now SDK generation breaks downstream. A mobile client gets stale types. QA finds the issue two days later.
The agent did not fail because it cannot code. It failed because the harness never told it:
API behavior changes require OpenAPI updates, SDK regeneration, and contract validation.
That rule should not live in someone’s memory. It should live in the enterprise harness.
The Enterprise Harness Adds Local Knowledge
A useful enterprise harness includes:
Repo maps
Architecture rules
Service ownership
Danger zones
Approved commands
Test strategy
Schema and API contracts
Deployment constraints
Security rules
Migration rules
Review checklist
Failure memory
This does not need to start as a big platform.
A good AGENTS.md, CLAUDE.md, or .cursor/rules file beats a 40-page wiki the model will not reliably use.
Example:
# Agent Rules
- Use pnpm, never npm.
- Do not edit legacy/payments/ without approval.
- API response changes must update openapi.yaml.
- Database migrations require a rollback note.
- Do not change test assertions just to make tests pass.
- For billing changes, run pnpm test:billing and pnpm test:contracts.
That is not documentation.
That is a pilot checklist.
Multi-Repo Research Needs Subagents
In enterprise systems, the first job is often not coding. It is research.
The question is rarely:
Change this file.
It is usually:
Figure out how this workflow moves through five repos, then make the smallest safe change.
This is where subagents help.
A single agent with one context window can get bloated fast. It reads the API repo, frontend repo, shared package, deployment repo, and test logs. Soon the context is full of half-useful details.
A better harness spawns focused subagents.
Example:
API research agent:
- Inspect orders-service.
- Find endpoint behavior.
- Identify contract files and tests.
Frontend research agent:
- Inspect admin-ui.
- Find where order details render.
- Identify SDK usage.
Shared package agent:
- Inspect generated SDK package.
- Find regeneration command.
- Check publishing flow.
Test agent:
- Find relevant unit, contract, and smoke tests.
- Return exact commands.
Each subagent gets a narrow task and its own context window. It returns a compact summary, not a transcript.
That keeps the main agent focused.
 Each branch returns a small summary card back to the planner.
Each branch returns a small summary card back to the planner.
Skills Keep Tokens Low
Skills are underrated.
A skill is a repeatable procedure the agent can load only when needed. It keeps the main prompt small and avoids dumping every rule into every task.
For example:
api-change-skill
db-migration-skill
billing-domain-skill
frontend-smoke-test-skill
terraform-change-skill
release-checklist-skill
When the task touches an API, the harness loads the API skill. When it touches a migration, it loads the migration skill. When it touches billing, it loads billing rules.
This matters because enterprise rules are large. If every rule goes into every context window, the assistant gets slower, more expensive, and less precise.
Good skills are short and operational.
Example:
# API Change Skill
Use when changing request/response behavior.
Steps:
1. Find route/controller.
2. Check openapi.yaml.
3. Update generated SDK if needed.
4. Run contract tests.
5. Check backward compatibility.
6. Report changed files and commands run.
That is better than a giant architecture document.
The right skill at the right time beats a bloated prompt.
Context Compaction Is Not Optional
Long enterprise tasks drift.
The agent starts with a clear goal. Then it reads files, runs tests, fixes errors, opens more files, and follows side paths. After enough turns, the context window gets noisy.
At that point, I prefer controlled compaction.
The harness should detect when the context reaches a threshold, then create a compact handoff and spawn a fresh agent.
The handoff should include:
Original goal
Current plan
Files changed
Files inspected
Important findings
Commands run
Failures seen
Open risks
Next recommended step
Not the full chat.
Not every log line.
Just the state needed to continue.
Example handoff:
# Handoff Summary
Goal:
Add deliveryWindow to order details API and admin UI.
Findings:
- API endpoint: orders-service/src/routes/orderDetails.ts
- Contract: contracts/openapi.yaml
- UI component: admin-ui/src/components/OrderDetails.tsx
- SDK generated from openapi.yaml.
Changed:
- orderDetails.ts
- openapi.yaml
Commands run:
- pnpm test:orders passed
- pnpm validate:openapi failed
Current issue:
SDK generation fails because deliveryWindow is missing from OrderDetails schema.
Next step:
Fix schema, regenerate SDK, run admin typecheck.
A fresh agent with this summary is usually better than an exhausted agent dragging a full conversation behind it.
 Compaction creates handoff summary.”
Right: “New focused agent continues with clean context.”
Compaction creates handoff summary.”
Right: “New focused agent continues with clean context.”
Tools Should Hide Tribal Commands
Do not make the agent rediscover your commands every run.
This is weak:
Run the right tests.
This is better:
{
"tool": "run_service_tests",
"args": {
"service": "billing-api",
"scope": "changed-files"
}
}
Enterprise commands are often ugly.
Real command:
TENANT_ID=local-dev REGION=us-east-1 pnpm --filter billing-api test:integration -- --runInBand
Agent-facing tool:
run_billing_integration_tests
That wrapper saves tokens and prevents mistakes.
It also lets you enforce policy. The tool can block production credentials, require staging mode, or refuse destructive migration commands.
The Evaluator Should Not Be The Coder
The coding agent should not be the only judge of success.
For low-risk changes, lint and tests may be enough. For higher-risk work, add a reviewer agent or evaluator checklist.
Example evaluator for an API change:
- Did public behavior change?
- Was openapi.yaml updated?
- Was the SDK regenerated?
- Were contract tests run?
- Did the diff touch unrelated files?
- Was backward compatibility considered?
Use deterministic checks first.
Tests beat opinions. Typechecks beat confidence. Schema validation beats “looks good.”
A browser smoke test beats a screenshot that looks plausible.
Brownfield Example: Adding A Field
Task:
Add deliveryWindow to the order details API and show it in the admin UI.
A naive agent changes the backend DTO and React component. The UI works locally. It stops there.
A domain-aware harness does more.
It loads the API change skill. It spawns a frontend research agent. It asks a test agent for the right commands. It compacts context once the research phase is done.
The final implementation checklist becomes:
Update API response.
Update openapi.yaml.
Regenerate SDK.
Update admin UI.
Run order-service tests.
Run contract tests.
Run admin typecheck.
Report evidence.
The final response should include proof:
Changed:
- orders-service/src/orderDetails.ts
- contracts/openapi.yaml
- packages/sdk/src/generated/orders.ts
- apps/admin/src/components/OrderDetails.tsx
Checks:
- pnpm validate:openapi passed
- pnpm test:orders passed
- pnpm --filter admin typecheck passed
That is the difference between code generation and engineering assistance.
[Image idea 4: Before/after checklist]
Before: “Changed DTO + UI, said done.”
After: “Contract updated, SDK regenerated, tests passed, evidence reported.”
The Harness Should Improve From Failures
The best teams will not just create rules. They will improve rules from real failures.
A small loop is enough:
Every week:
- Pick 20 real repo tasks.
- Run the coding assistant.
- Record pass/fail.
- Record missed rules.
- Record wrong files touched.
- Record tool failures.
- Turn repeated misses into harness changes.
Example:
Failure:
Agent repeatedly forgets to update generated SDK after OpenAPI changes.
Harness fix:
- Add API-change skill.
- Add validate_openapi tool.
- Add SDK generation check.
- Add evaluator checklist item.
- Add one regression eval task.
That is harness engineering.
Not magic self improvement. Just a feedback system where mistakes become better scaffolding.
What I Would Build First
For an enterprise brownfield environment, I would start with seven things:
1. Root agent rules file
2. Repo and service map
3. Skill library for common change types
4. Subagent pattern for multi-repo research
5. Context compaction and handoff template
6. Approved command/tool registry
7. Small eval set from real past bugs
That is enough to change the quality of output.
Then I would add specialized agents:
Planner agent: breaks down the task.
Research agents: inspect separate repos or domains.
Coder agent: makes the change.
Test agent: finds and runs focused checks.
Reviewer agent: checks contracts, architecture, and risk.
Docs agent: updates handoff notes or README changes.
Use subagents where the repo shape demands it.
In a single small repo, one agent may be enough. In an enterprise system with API, frontend, SDK, infra, and test repos, subagents are practical. They keep each research thread focused and return compact summaries instead of bloating the main context.
The rule is simple: use subagents when the work crosses repo boundaries, domain boundaries, or validation boundaries.
The Trade-Off
A stronger harness costs time.
It adds skills, wrappers, summaries, evaluators, and maintenance. It can also over-constrain the assistant. Too much process turns the agent into a slow checklist machine.
So keep it small.
Only encode rules that prevent real damage or repeated waste. If a rule has never caught a bug, prevented a bad diff, or saved review time, it probably does not belong in the critical path.
The Takeaway
The next advantage in AI coding will not come only from picking the newest model.
Everyone will have strong models. Everyone will have Cursor, Claude Code, Copilot, Codex, or whatever comes next.
The advantage will come from the local harness.
The team that teaches its assistant the repos, contracts, skills, danger zones, test commands, deployment rules, and failure history will get better output from the same model.
For greenfield work, the base harness may be enough.
For brownfield enterprise work, you need another layer.
Not a bigger prompt.
A domain-aware harness.
%22%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%220%25%22%20stop-color%3D%22%237c3aed%22%2F%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%22100%25%22%20stop-color%3D%22%231e1b4b%22%2F%3E%0A%20%20%20%20%3C%2FlinearGradient%3E%0A%20%20%20%20%3CradialGradient%20id%3D%22halo%22%20cx%3D%220.279%22%20cy%3D%220.316%22%20r%3D%220.55%22%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%220%25%22%20stop-color%3D%22rgba(255%2C255%2C255%2C0.32)%22%2F%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%2260%25%22%20stop-color%3D%22rgba(255%2C255%2C255%2C0)%22%2F%3E%0A%20%20%20%20%3C%2FradialGradient%3E%0A%20%20%3C%2Fdefs%3E%0A%20%20%3Crect%20width%3D%22800%22%20height%3D%22500%22%20fill%3D%22url(%23g)%22%2F%3E%0A%20%20%3Crect%20width%3D%22800%22%20height%3D%22500%22%20fill%3D%22url(%23halo)%22%2F%3E%0A%20%20%3Cg%20fill%3D%22rgba(255%2C255%2C255%2C0.12)%22%20stroke%3D%22rgba(255%2C255%2C255%2C0.18)%22%20stroke-width%3D%221%22%3E%0A%20%20%20%20%3Ccircle%20cx%3D%22223%22%20cy%3D%22158%22%20r%3D%2283%22%2F%3E%0A%20%20%20%20%3Ccircle%20cx%3D%22577%22%20cy%3D%22342%22%20r%3D%2233%22%2F%3E%0A%20%20%3C%2Fg%3E%0A%20%20%3Ctext%20x%3D%2250%25%22%20y%3D%2252%25%22%20text-anchor%3D%22middle%22%20dominant-baseline%3D%22middle%22%0A%20%20%20%20%20%20%20%20font-family%3D%22Inter%2C%20system-ui%2C%20sans-serif%22%20font-weight%3D%22800%22%0A%20%20%20%20%20%20%20%20font-size%3D%22170%22%20fill%3D%22rgba(255%2C255%2C255%2C0.92)%22%20letter-spacing%3D%22-6%22%3ETA%3C%2Ftext%3E%0A%20%20%3Ctext%20x%3D%2250%25%22%20y%3D%2278%25%22%20text-anchor%3D%22middle%22%0A%20%20%20%20%20%20%20%20font-family%3D%22Inter%2C%20system-ui%2C%20sans-serif%22%20font-weight%3D%22700%22%0A%20%20%20%20%20%20%20%20font-size%3D%2222%22%20letter-spacing%3D%226%22%0A%20%20%20%20%20%20%20%20fill%3D%22rgba(255%2C255%2C255%2C0.78)%22%3EAI%3C%2Ftext%3E%0A%3C%2Fsvg%3E)
%22%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%220%25%22%20stop-color%3D%22%237c3aed%22%2F%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%22100%25%22%20stop-color%3D%22%231e1b4b%22%2F%3E%0A%20%20%20%20%3C%2FlinearGradient%3E%0A%20%20%20%20%3CradialGradient%20id%3D%22halo%22%20cx%3D%220.171%22%20cy%3D%220.336%22%20r%3D%220.55%22%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%220%25%22%20stop-color%3D%22rgba(255%2C255%2C255%2C0.32)%22%2F%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%2260%25%22%20stop-color%3D%22rgba(255%2C255%2C255%2C0)%22%2F%3E%0A%20%20%20%20%3C%2FradialGradient%3E%0A%20%20%3C%2Fdefs%3E%0A%20%20%3Crect%20width%3D%22800%22%20height%3D%22500%22%20fill%3D%22url(%23g)%22%2F%3E%0A%20%20%3Crect%20width%3D%22800%22%20height%3D%22500%22%20fill%3D%22url(%23halo)%22%2F%3E%0A%20%20%3Cg%20fill%3D%22rgba(255%2C255%2C255%2C0.12)%22%20stroke%3D%22rgba(255%2C255%2C255%2C0.18)%22%20stroke-width%3D%221%22%3E%0A%20%20%20%20%3Ccircle%20cx%3D%22137%22%20cy%3D%22168%22%20r%3D%2287%22%2F%3E%0A%20%20%20%20%3Ccircle%20cx%3D%22663%22%20cy%3D%22332%22%20r%3D%2247%22%2F%3E%0A%20%20%3C%2Fg%3E%0A%20%20%3Ctext%20x%3D%2250%25%22%20y%3D%2252%25%22%20text-anchor%3D%22middle%22%20dominant-baseline%3D%22middle%22%0A%20%20%20%20%20%20%20%20font-family%3D%22Inter%2C%20system-ui%2C%20sans-serif%22%20font-weight%3D%22800%22%0A%20%20%20%20%20%20%20%20font-size%3D%22170%22%20fill%3D%22rgba(255%2C255%2C255%2C0.92)%22%20letter-spacing%3D%22-6%22%3EOA%3C%2Ftext%3E%0A%20%20%3Ctext%20x%3D%2250%25%22%20y%3D%2278%25%22%20text-anchor%3D%22middle%22%0A%20%20%20%20%20%20%20%20font-family%3D%22Inter%2C%20system-ui%2C%20sans-serif%22%20font-weight%3D%22700%22%0A%20%20%20%20%20%20%20%20font-size%3D%2222%22%20letter-spacing%3D%226%22%0A%20%20%20%20%20%20%20%20fill%3D%22rgba(255%2C255%2C255%2C0.78)%22%3EAI%3C%2Ftext%3E%0A%3C%2Fsvg%3E)
%22%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%220%25%22%20stop-color%3D%22%237c3aed%22%2F%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%22100%25%22%20stop-color%3D%22%231e1b4b%22%2F%3E%0A%20%20%20%20%3C%2FlinearGradient%3E%0A%20%20%20%20%3CradialGradient%20id%3D%22halo%22%20cx%3D%220.149%22%20cy%3D%220.334%22%20r%3D%220.55%22%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%220%25%22%20stop-color%3D%22rgba(255%2C255%2C255%2C0.32)%22%2F%3E%0A%20%20%20%20%20%20%3Cstop%20offset%3D%2260%25%22%20stop-color%3D%22rgba(255%2C255%2C255%2C0)%22%2F%3E%0A%20%20%20%20%3C%2FradialGradient%3E%0A%20%20%3C%2Fdefs%3E%0A%20%20%3Crect%20width%3D%22800%22%20height%3D%22500%22%20fill%3D%22url(%23g)%22%2F%3E%0A%20%20%3Crect%20width%3D%22800%22%20height%3D%22500%22%20fill%3D%22url(%23halo)%22%2F%3E%0A%20%20%3Cg%20fill%3D%22rgba(255%2C255%2C255%2C0.12)%22%20stroke%3D%22rgba(255%2C255%2C255%2C0.18)%22%20stroke-width%3D%221%22%3E%0A%20%20%20%20%3Ccircle%20cx%3D%22119%22%20cy%3D%22167%22%20r%3D%2269%22%2F%3E%0A%20%20%20%20%3Ccircle%20cx%3D%22681%22%20cy%3D%22333%22%20r%3D%2249%22%2F%3E%0A%20%20%3C%2Fg%3E%0A%20%20%3Ctext%20x%3D%2250%25%22%20y%3D%2252%25%22%20text-anchor%3D%22middle%22%20dominant-baseline%3D%22middle%22%0A%20%20%20%20%20%20%20%20font-family%3D%22Inter%2C%20system-ui%2C%20sans-serif%22%20font-weight%3D%22800%22%0A%20%20%20%20%20%20%20%20font-size%3D%22170%22%20fill%3D%22rgba(255%2C255%2C255%2C0.92)%22%20letter-spacing%3D%22-6%22%3EAI%3C%2Ftext%3E%0A%20%20%3Ctext%20x%3D%2250%25%22%20y%3D%2278%25%22%20text-anchor%3D%22middle%22%0A%20%20%20%20%20%20%20%20font-family%3D%22Inter%2C%20system-ui%2C%20sans-serif%22%20font-weight%3D%22700%22%0A%20%20%20%20%20%20%20%20font-size%3D%2222%22%20letter-spacing%3D%226%22%0A%20%20%20%20%20%20%20%20fill%3D%22rgba(255%2C255%2C255%2C0.78)%22%3EAI%3C%2Ftext%3E%0A%3C%2Fsvg%3E)